URL重写技术细节
本文探讨一些mod_rewrite和URL匹配的技术细节。

内部处理
此模块的内部处理极为复杂,但是为了使一般用户避免犯低级错误,也让管理员能充分利用其功能,在此仍然做一下说明。
API阶段
首先,你必须了解apache是分若干阶段来处理Http请求的。Apache API对每个阶段都提供了一个hook程序。mod_rewrite使用两个hook程序:其一,从URL到文件名的转换hook(用在读取HTTP请求之后、授权开始之前); 其二,修正hook(用在授权阶段和读取目录级配置(.htAccess)之后、内容处理器激活之前)。
所以,Apache收到一个请求并且确定了响应主机(或虚拟主机)之后,重写引擎即开始处理服务器级配置中的所有mod_rewrite指令(此时处于从URL到文件名转换的阶段),此阶段完成后,最终的数据目录便确定了。接下来进入修正程序段并触发目录级配置中的mod_rewrite指令。这两个阶段并不是泾渭分明的,但都实施了把URL重写成新的URL或者文件名。虽然API最初不是为此目的而设计的,但是现在它已经成为了API的一种用途。记住以下两点,会有助于更好地理解:
- 虽然
mod_rewrite可以将URL重写为新的URL或文件名,甚至将文件名重写为新的文件名,但是之前的API只提供从URL到文件名的hook。在Apache 2.0中,增加了两个丢失的hook以使得处理过程更加清晰。不过这样做并没有给用户带来麻烦,用户只需记住这样一个事实:借助从URL到文件名的hook比最初API设计的目标功能更强大。 - 令人难以置信的是,
mod_rewrite还提供了目录级的URL操作(.htaccess文件),而这些文件必须在将URL转换成文件名之后才会被处理(这是必须的,因为.htaccess存在于文件系统中)。换句话说,根据API阶段,这时再处理任何URL操作已经太晚了。为了解决这个"鸡和蛋"的问题,mod_rewrite使用了一个小技巧:在进行一个目录级的URL/文件名操作时,先把文件名重写回相应的URL(通常这个操作是不可行的,但是参考下面的RewriteBase指令就能明白它是怎么实现的了),然后,对这个新的URL建立一个新的内部的子请求,再重新开始API阶段的执行。另外,
mod_rewrite尽力使这些复杂的操作对用户透明。但仍须记住:服务器级的URL操作速度快而且效率高,而目录级的操作由于这个"鸡和蛋"的问题速度较慢而且效率也低。但从另一个侧面看,这却是mod_rewrite得以为一般用户提供(局部限制的)URL操作的唯一方法。
牢记这两点!
规则集的处理
当mod_rewrite在这两个API阶段中开始执行时,它会读取配置结构中配置好的 (或者是在服务启动时建立的服务器级的,或者是在遍历目录采集到的目录级的)规则集,然后,启动URL重写引擎来处理(带有一个或多个条件的)规则集。无论是服务器级的还是目录级的规则集,都是由同一个URL重写引擎处理,只是最终结果处理不同而已。
规则集中规则的顺序是很重要的,因为重写引擎是按一种特殊的顺序处理的:逐个遍历每个规则(RewriteRule指令),如果出现一个匹配条件的规则,则可能回头遍历已有的规则条件(RewriteCond指令)。由于历史的原因,条件规则是前置的,所以控制流程略显冗长,细节见图-1。
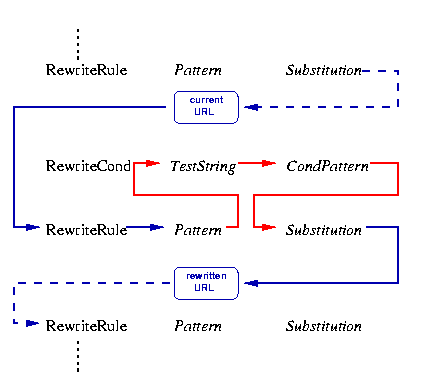
图-1:重写规则集中的控制流
可见,URL首先与每个规则的Pattern匹配,如果匹配失败,mod_rewrite将立即终止此规则的处理,继而处理下一个规则。如果匹配成功,mod_rewrite将寻找相应的规则条件,如果一个条件都没有,则简单地用Substitution构造的新值来替换URL,然后继续处理其他规则;但是如果条件存在,则开始一个内部循环按其列出的顺序逐个处理。对规则条件的处理有所不同:URL并不与模式进行匹配,而是首先通过扩展变量、反向引用、查找映射表等步骤建立一个TestString字符串,然后用它来与CondPattern匹配。如果匹配失败,则整个条件集和对应的规则失败;如果匹配成功,则执行下一个规则直到所有条件执行完毕。如果所有条件得以匹配,则以Substitution替换URL,并且继续处理。